Table of Contents
Data can take various forms and there are different ways of its extraction and interpretation. Google Cloud platform has major products in the field of data processing and data warehousing. Google Cloud Dataflow and Dataproc are new age data processing tools in the cloud.
Today we look more in detail about Google Cloud Dataflow and Dataproc products for data processing which perform separate sets of tasks but are still interrelated to each other. This article will give insight into the major differences between the two, its purpose for which they are deployed and use cases.
What is Google Dataflow?
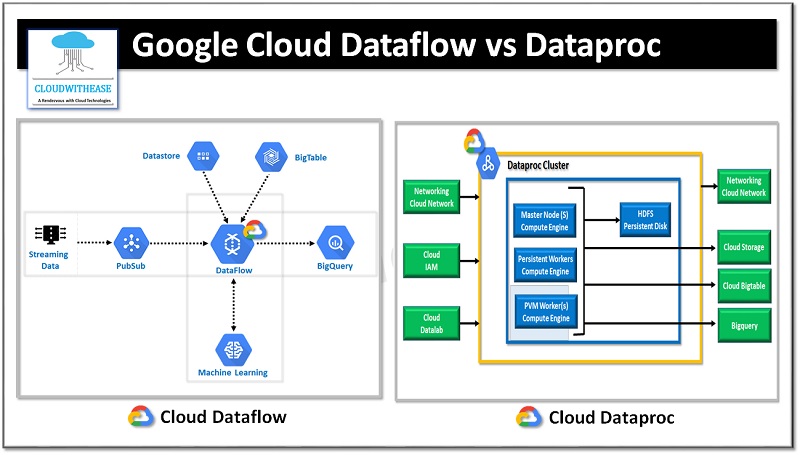
Google Dataflow is meant to simplify Big data. It can manage and operate batch and stream data processing. Programming and execution frameworks are merged to achieve parallelization. Cluster data is not kept idle in Dataflow instead cluster is monitored continuously and remodelling is performed according to the algorithm being used. Dataflow permits APACHE Beam tasks with in built function to run on Google cloud.

Features of Google Cloud Dataflow
The key features of Dataflow are:
- Extract, transform and load (ETL) data into multiple data warehouses simultaneously.
- MapReduce require Dataflow to handle large number of parallelization tasks.
- Scan real time, user, management , financials or retail sales data.
- Processing immense amounts of data for research and predictive analysis with data science techniques. Such as genome mapping, weather forecasting, and financial data .
Use cases for Cloud Dataflow
- Google stream analytics
- Real time AI
What is Google Cloud Dataproc?
It is a Google cloud product with Data science / ML for Spark and Hadoop. It is UI driven, scales on demand and fully automated solution. Many organizations are using Spark and Hadoop but this is leading to overhead and overly complex configurations which are proven to be costly and complicated. So even if you don’t want to use a particular cluster in Big data, you still pay for it.
In Google cloud platform you can migrate the entire deployment of Spark/Hadoop to completely managed services. Mechanically clusters can be created and managed in Dataflow. It has built in reports and you can shutdown or remove clusters on demand.
Dataproc Clusters are of two types:
- Clusters which are provisioned on Google Cloud Platform. First one is called an ephemeral cluster (define cluster when a job is submitted, scaled up or down as needed by the job, and is deleted post job completion).
- The other type is the long-standing cluster, where the user creates a cluster (Similar to an on-premise cluster) having a set number of minimal and maximum count of nodes. It allows both horizontal scaling such as 1000 of nodes per cluster as well as vertical scaling such as configurable system machine types, GPUs, drive storage, and persistent disks etc.

Features of Google Dataproc
The key features of Dataproc are:
- Using existing MapReduce, you can operate on immense data sets without any worry for overhead.
- Has a built in monitoring system , to transfer your cluster data to applications.
- Quick way to get reports and have feature of storing data in Google BigQuery.
- Quicker launch and deletion of smaller clusters stored in blob storage as and when required using Spark (Spark SQL, PySpark, Spark Shell).
- Customization and classification of algorithms using Spark Machine learning library and data science.
Use cases for Google Dataproc
- Moving Hadoop and Spark clusters to cloud
- Data science using Dataproc
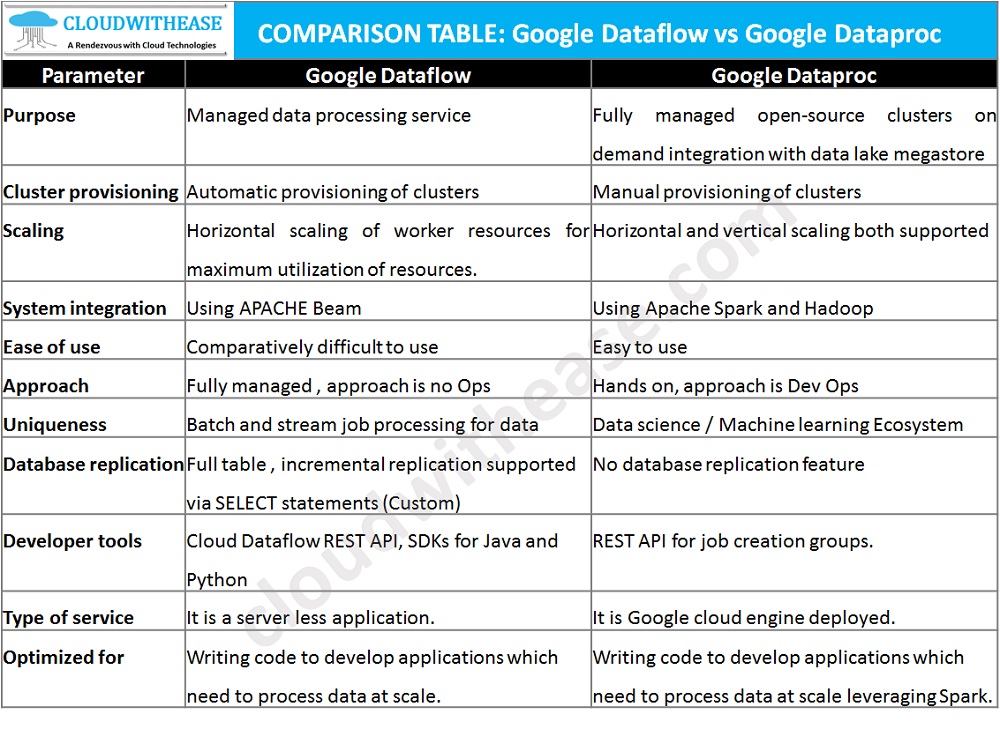
Comparison Table: Google Cloud Dataflow vs Dataproc
Below table summarizes the key difference between the Google Data flow and Dataproc data processing tools in the cloud:
Download the comparison table: Google Cloud Dataflow vs Dataproc