Table of Contents
Snowflake is a cloud-based data warehousing platform that runs on various cloud providers, including AWS, Azure, and Google Cloud Platform. It is known for its unique architecture that separates compute and storage, enabling elastic scalability and high performance. While Snowflake can be deployed on AWS infrastructure, it is not a native AWS service.
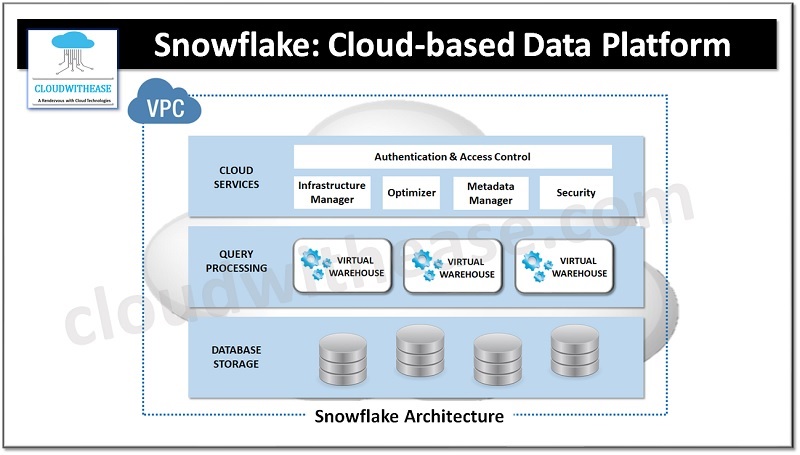
Snowflake Architecture
Here’s a description of Snowflake’s architecture:
Compute Layer
The compute layer in Snowflake is responsible for query processing and execution. It consists of virtual warehouses, which are clusters of compute resources that execute queries in parallel. Snowflake’s architecture allows for scaling compute resources independently of storage, providing elasticity and enabling on-demand performance scaling.
Storage Layer
The storage layer in Snowflake is where data is stored. Snowflake employs an object-based storage model, utilizing Amazon S3 (Simple Storage Service) as the underlying storage for data persistence. Data is stored in multiple micro-partitions, which are immutable and compressed data files. The separation of compute and storage allows for decoupling of storage capacity from computational resources.
Metadata Layer
The metadata layer in Snowflake manages the metadata associated with the data stored in the platform. It includes information about tables, schemas, views, and user-defined functions. The metadata layer also tracks the metadata for query optimization, query planning, and execution. Snowflake’s metadata layer is highly distributed and scalable to support large-scale deployments.
Query Processing
When a query is submitted to Snowflake, the query is parsed, optimized, and compiled into a query plan. The query planner analyzes the query and optimizes it for parallel execution across the compute resources. Snowflake’s optimizer utilizes statistics and metadata to generate an optimal execution plan for efficient query processing.
Multi-Cluster Shared Data Architecture
Snowflake’s architecture allows for multiple virtual warehouses to operate on the same underlying data simultaneously. This multi-cluster shared data architecture enables workload isolation, performance scaling, and efficient resource utilization. Each virtual warehouse can be scaled independently based on the workload requirements.
Data Protection and Security
Snowflake provides robust security features to protect data. It offers end-to-end encryption for data in transit and at rest. Snowflake also supports fine-grained access controls, authentication mechanisms, and integration with AWS Identity and Access Management (IAM) for user management and authorization.
Data Sharing
Snowflake allows for easy and secure data sharing between organizations and users. Data providers can share read-only or read-write access to their data with other Snowflake accounts. This data sharing capability simplifies data collaboration and eliminates the need for complex data exports and imports.
Snowflake’s architecture is designed to provide scalability, elasticity, and high-performance analytics processing on the cloud. It leverages cloud-native storage and computing capabilities to offer a flexible and efficient data warehousing solution.
How to set up a Virtual Warehouse Using Snowflake?
To set up a virtual warehouse in Snowflake, you need to follow these steps:
Access Snowflake
Access the Snowflake web interface or use a Snowflake client tool, such as Snowflake SQL Alchemy or SnowSQL, to connect to your Snowflake account.
Create a Database
If you haven’t already done so, create a database where your virtual warehouse will reside. You can use the following SQL command to create a database:
CREATE DATABASE <database_name>;
Create a Warehouse
To create a virtual warehouse, you can use the following SQL command:
CREATE WAREHOUSE <warehouse_name>
WITH
WAREHOUSE_SIZE = ‘<size>’,
AUTO_SUSPEND = <suspend_time_in_seconds>,
AUTO_RESUME = <resume_time_in_seconds>,
MIN_CLUSTER_COUNT = <min_cluster_count>,
MAX_CLUSTER_COUNT = <max_cluster_count>,
SCALING_POLICY = ‘<scaling_policy>’;
Here are the parameters you need to specify:
<warehouse_name>: The name of the virtual warehouse you want to create.
<size>: The size of the warehouse, which determines the amount of compute resources allocated to it. Sizes range from X-Small to 4X-Large.
<suspend_time_in_seconds>: The number of seconds of inactivity before the warehouse automatically suspends. This helps save costs by pausing the warehouse when not in use.
<resume_time_in_seconds>: The number of seconds before the warehouse automatically resumes after being suspended.
<min_cluster_count>: The minimum number of compute clusters allocated to the warehouse. This helps ensure a minimum level of performance.
<max_cluster_count>: The maximum number of compute clusters that can be dynamically added to the warehouse based on workload demands.
<scaling_policy>: The scaling policy that determines how the warehouse scales in response to changing workload requirements. Options include STANDARD, ECONOMY, or FIXED.
Start the Warehouse
Once the virtual warehouse is created, you can start it using the following SQL command:
ALTER WAREHOUSE <warehouse_name> RESUME;
This command activates the virtual warehouse and makes it available for processing queries.
Use the Warehouse
You can now use the virtual warehouse for executing SQL queries. Set the virtual warehouse as the current warehouse using the following SQL command:
USE WAREHOUSE <warehouse_name>;
All subsequent queries will utilize the resources of the specified virtual warehouse.
Monitor and Manage
You can monitor the performance and usage of your virtual warehouse through the Snowflake web interface or by querying system tables and views. Use the following SQL command to view the status and details of your virtual warehouse:
SHOW WAREHOUSES;
You can also modify the properties of the virtual warehouse, such as resizing it or changing the scaling policy, using the ‘ALTER WAREHOUSE’ command.
Remember to manage your virtual warehouses based on your workload requirements. Suspending or resizing warehouses during periods of low activity can help optimize costs, while adjusting the cluster count can accommodate fluctuating workload demands.
Please note that Snowflake provides more advanced configuration options and capabilities for virtual warehouses. It’s recommended to refer to the Snowflake documentation for a comprehensive understanding of warehouse management and to explore additional features, such as multi-cluster warehouses and resource monitors.