Table of Contents
While migrating to cloud infrastructure other than compute, networking, storage etc. database migrations are also one of key components. Database migration services allow to move on premises relational data onto the cloud. Cloud providers offer a variety of database options to suit your organization needs.
In the last blog, we discussed Google cloud storage options. Today we look more in detail about Google cloud database services and its features, how it works, use cases and so on.
Data Types: Structured & Unstructured Data
Before discussing the Google Cloud database services options, we should be familiar with the data types. The Google cloud database services can be categorized as:
1.) Structured Data:
It is the one in which the data can be organized in a structural format like rows and columns. E.g.- Cloud SQL, Cloud Spanner, Cloud Bigtable, Cloud BigQuery database services store data in a structured form.
2.) Unstructured Data:
It involves a sequence of bytes (video, image, or document). The unstructured data is stored as objects in buckets and no insight can be fetched. E.g.- Cloud Firestore database service stores data in an unstructured form.
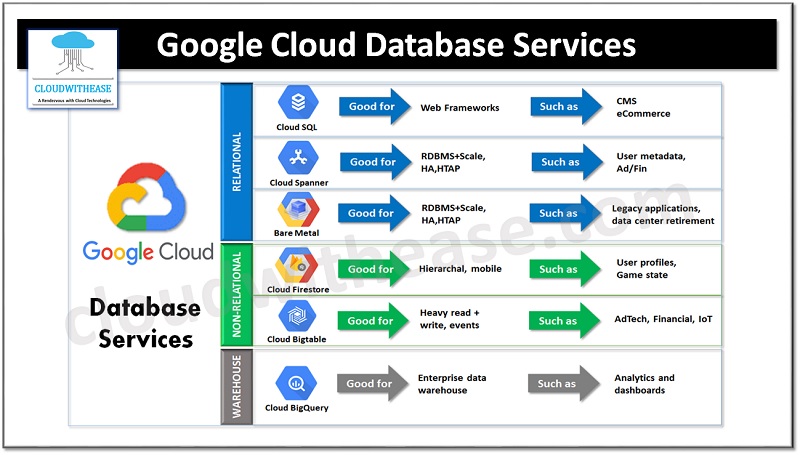
What are Google Cloud Database services?
Google offers various database options to suit your business needs. We will look at the different database options available in Google cloud: Relational (SQL) databases, Non-relational (NoSQL) databases and Data warehouse.
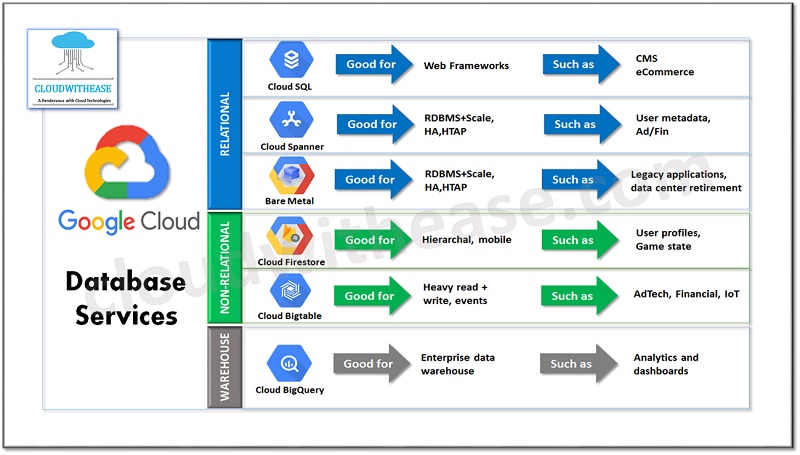
Relational (SQL) databases
In relational database services, the data is stored in a structural format like rows and columns. Relational databases use Structured Query Language or SQL. The relational database options in Google Cloud are:
Cloud SQL
It is a managed MySQL database. The second generation of cloud SQL currently in beta supports MySQL 5.6 and 5.7. The available instance sizes are ranging from 10 GB to 10 TB with up to 16 vCPUs and 104 GB of RAM. Zone redundancy is built in (automated). Ideally suited for monolithic OLTP applications such as content management systems, Enterprise resource planning (ERP) and Customer relationship management (CRM).
Advantages:
Using Cloud SQL has some advantages such as
- lower maintenance costs,
- provides backup and disaster recovery,
- encryption and firewall protection,
- ease of management,
- ease of integration and so on.
Disadvantages:
However, it has certain limitations such as,
- If you need to increase IOPS beyond 10K or store data more than 10 TB you cannot achieve that by simply adding a new node.
- There is no horizontal write scalability in cloud SQL so you have to rewrite the application.
Cloud Spanner
Cloud Spanner is a globally distributed highly available relational service with single and multi-region deployment configurations. Inserts and updates are using a custom API which reads DDL operations using a spanner specific flavour of SQL.
- It offers automatic, synchronous replication within and across regions for high availability.
- It is ideal for distribution of OLTP Apps like retail product catalogue, SaaS user identity and online games.
Bare Metal Solution
This solution is used particularly if you want to shift Oracle databases into Google cloud. Bare metal solution thus helps to run the specialized workloads with low latency on Google Cloud.
- It enables data center retirements.
- Facilitate the modernization of legacy applications.
Non-Relational (NoSQL) databases
In non-relational database services, the data is stored in an unstructured non-tabular format. Non-Relational databases do not use SQL. The non-relational database options in Google Cloud are:
Cloud Firestore
Cloud Firestore is a NoSQL service where there are no tables, or rows instead data is stored in documents which are organized into collections.
- It supports native SDKs for web, Android and iOS apps.
- It has powerful querying capabilities and has a document-oriented data model.
- Cloud Filestore is ideal for building client side mobile and web applications, gaming leaderboards, and global scale user presence.
Cloud Bigtable
Large scale workload processing is the best bet for Bigtable NoSQL stores. Bigtable is a hardened database which is used by many Google owned products.
- It has an APACHE HBase API, and it can integrate with Hadoop and other big data products. It has two options: SSD and HDD backend storage.
- With SSD it supports 10,000 queries per second on a single node cluster with a linear improvement in performance as more nodes are added.
- Bigtable only supports one index per table, updates only atomic at row level and it has no built-in replication within zones or across regions.
- It is good for time series like Hybrid transactional /Analytical processing (HTAP) apps which do not require multi-region deployments.
Advantages:
- It has some advantages however such as
- It gives high throughput over low latency,
- you can add or remove cluster nodes without restart and no downtime,
- write data once and replicate where needed,
- gives consistency and control for high availability and isolation of read and write workloads. No manual intervention needed to repair data, synchronize writes and deletes.
Data Warehouse Database
Cloud BigQuery
Cloud BigQuery is Google’s fully managed, petabyte scalable data warehousing service. Data is loaded via job or REST API. Near real-time analytics is supported via streaming. Customers pay for usage of storage based on number of queries and number of streaming inserts. Data residing in BigQuery is automatically replicated across data centres in a single region. Caching is provided by Memcache, which is part of the APP engine product.