Table of Contents
Amazon Redshift is a fully managed cloud-based data warehousing service provided by Amazon Web Services (AWS). It is designed for processing and analyzing large-scale datasets in a fast, scalable, and cost-effective manner. Redshift offers high-performance querying capabilities, columnar storage, and parallel processing, making it suitable for data analytics, business intelligence, and reporting purposes.
Key Features of AWS Redshift
Here are some key aspects and features of AWS Redshift:
- Columnar Storage: Redshift stores data in a columnar format, which allows for efficient compression, reduced I/O, and improved query performance. By storing data column-wise rather than row-wise, Redshift can selectively read only the necessary columns during query execution, optimizing data retrieval.
- Massively Parallel Processing (MPP): Redshift leverages MPP architecture, distributing and parallelizing query execution across multiple compute nodes. This enables faster query performance by dividing the workload across the cluster and executing operations in parallel.
- Scalability and Elasticity: Redshift offers scalability to handle growing data volumes and changing workloads. You can easily scale your Redshift cluster by adding or removing compute nodes to match your performance and storage requirements. Redshift’s elasticity allows you to resize your cluster or pause it during periods of low activity to optimize costs.
- Fully Managed Service: AWS manages the underlying infrastructure, maintenance, backups, and software updates for Redshift, allowing you to focus on data analysis and insights rather than infrastructure management. Automated backups and snapshots ensure data durability and enable point-in-time recovery.
- Integration with AWS Ecosystem: Redshift seamlessly integrates with other AWS services, such as Amazon S3 for data storage, AWS Glue for ETL (Extract, Transform, Load) processes, AWS Lambda for event-driven processing, and AWS Identity and Access Management (IAM) for access control. This integration facilitates building end-to-end data pipelines and analytics solutions within the AWS ecosystem.
- Security and Compliance: Redshift provides robust security features to protect data at rest and in transit. It supports encryption of data using AWS Key Management Service (KMS) and offers integration with IAM for access control. Redshift is compliant with various industry standards, including GDPR, HIPAA, and PCI DSS, enabling you to meet regulatory requirements.
- Concurrency and Workload Management: Redshift allows concurrent query execution, enabling multiple users and applications to run queries simultaneously. Redshift’s workload management (WLM) feature allows you to prioritize and allocate resources to different workloads based on query queues, ensuring performance and resource optimization.
- Easy Integration with BI Tools: Redshift is compatible with various popular business intelligence (BI) and reporting tools, including Tableau, Power BI, and Looker. You can connect these tools directly to Redshift to visualize and analyze data stored in your data warehouse.
AWS Redshift offers a powerful and scalable solution for organizations looking to leverage the benefits of cloud-based data warehousing. It simplifies data management, improves query performance, and provides flexibility to accommodate changing business needs.
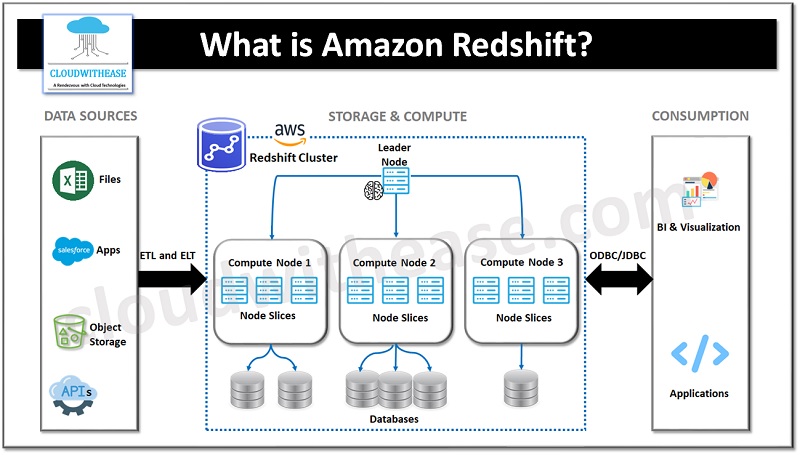
Understanding Amazon Redshift Architecture
The architecture of AWS Redshift consists of several key components:
Leader Node:
The leader node acts as the control node for the Redshift cluster. It manages client connections, receives queries, compiles and optimizes execution plans, and coordinates query execution across the compute nodes. The leader node does not store data and is responsible for managing metadata and query distribution.
Compute Nodes:
Redshift clusters consist of one or more compute nodes, which store and process data. Each compute node contains dedicated CPU, memory, and disk storage. Compute nodes are divided into slices, where each slice is a unit of parallel processing that handles a portion of the data and query workload.
Columnar Storage:
Redshift uses a columnar storage format, where data is stored in columnar blocks instead of traditional row-based storage. This columnar storage allows for efficient compression and encoding techniques, improving query performance and reducing storage requirements.
Massively Parallel Processing (MPP):
Redshift leverages MPP architecture, enabling it to distribute and parallelize queries across multiple compute nodes and slices. This parallel processing enables faster query execution by dividing the workload across the cluster and performing operations in parallel.
Data Distribution:
Redshift distributes data across compute nodes using a key-based distribution approach. Data is divided into smaller subsets based on the distribution key defined during table creation. Each subset of data is then assigned to a specific compute node for processing. This distribution mechanism enhances query performance by minimizing data movement during query execution.
Redshift Spectrum:
Redshift integrates with Amazon Redshift Spectrum, a feature that allows you to query data directly from Amazon S3. Redshift Spectrum leverages the same compute nodes and leader node of the Redshift cluster, enabling you to run queries that span both S3 data and Redshift data seamlessly.
Data Loading and Backup:
Redshift supports various data loading mechanisms, including bulk data ingestion, parallel loading, and direct querying of data stored in Amazon S3. Redshift also provides automated backups, allowing you to restore data to a specific point in time.
Security and Availability:
Redshift offers built-in security features such as encryption at rest and in transit, IAM integration for authentication and authorization, and VPC isolation for network security. It also provides high availability through automated snapshots, replication, and cross-region replication for disaster recovery.
Overall, the architecture of AWS Redshift is designed to provide high-performance analytics processing, scalability, and ease of use for handling large volumes of data in a data warehousing environment.
How to migrate to Amazon Redshift from Traditional Data Warehousing?
Here’s a description of the migration process:
- Assess and Plan: Start by assessing your existing data warehousing environment and understanding your requirements for migrating to Amazon Redshift. Evaluate the schema, data models, queries, and performance requirements. Identify the data sources, ETL (Extract, Transform, Load) processes, and any dependencies that need to be migrated.
- Design the Redshift Environment: Based on your assessment, design the Amazon Redshift environment. Determine the cluster configuration, including the number and size of compute nodes. Define the schema and data distribution strategy, considering the key-based distribution approach in Redshift. Plan for any required transformations or schema changes.
- Data Extraction: Extract the data from your traditional data warehousing system. This may involve exporting data from tables, views, or other data sources into intermediate files or staging tables. You can use ETL tools, custom scripts, or database utilities specific to your traditional data warehousing system to extract the data.
- Data Transformation: If necessary, transform the data to align with the schema and data models designed for Redshift. Perform any required data cleansing, restructuring, or aggregations. This step may involve using ETL tools or custom scripts to prepare the data for loading into Redshift.
- Data Loading: Load the transformed data into Amazon Redshift. Redshift provides various methods for data loading, including COPY command for bulk loading from files, INSERT command for small datasets, and direct querying of data stored in Amazon S3 using Redshift Spectrum. Choose the appropriate method based on your data volume and requirements.
- Migration Verification: Validate the data loaded into Redshift by running sample queries and comparing the results with your traditional data warehousing system. Ensure that the data has been accurately migrated and that the query results match your expectations.
- ETL and Application Integration: Modify your ETL processes, applications, or reporting tools to work with Redshift. Update connection strings, SQL queries, and any other integration points to connect to the Redshift cluster. Redshift is compatible with many standard SQL-based tools and frameworks, simplifying the integration process.
- Performance Optimization: Optimize your queries and data models for Redshift. Leverage Redshift’s features such as distribution keys, sort keys, and compression to improve performance. Rewrite queries to take advantage of Redshift’s parallel processing capabilities and columnar storage.
- Testing and Validation: Thoroughly test the migrated environment and validate the results against your expected outcomes. Verify the performance, query response times, and data consistency to ensure that the migration has been successful.
- Cut Over and Decommissioning: Once you are confident in the migrated Redshift environment, plan for the final cutover from your traditional data warehousing system to Redshift. Redirect your applications and users to start using Redshift as the new data warehousing solution. Monitor the system and gradually decommission the old environment as you confirm the successful adoption of Redshift.
Remember, each migration scenario can have unique considerations based on the specific requirements and technologies involved. It’s recommended to consult AWS documentation, best practices, and engage with AWS experts or consultants for a successful migration to Amazon Redshift.