Table of Contents
Business analytics and intelligent data analysis to derive better business outcomes is the call of the time. Organizations are enhancing data driven decision making and fostering an open culture where the data is not available in silos. Data analytics is important for a business to understand their customers’ needs in a better way, helps in making decisions on customer trends and behaviour prediction, increasing business profits and driving effective decision making.
Today we look more in detail about Google BigQuery, its benefits for data warehouse practitioners and use cases etc.
What is Google BigQuery?
Google BigQuery is a fully managed enterprise-wide data warehouse which helps to manage and analyse data with multiple features such as Machine learning, business analysis etc. It has zero infrastructure management costs and it uses SQL queries to analyse BigData. It is a scalable, distributed analysis engine which lets you query terabytes of data in seconds.
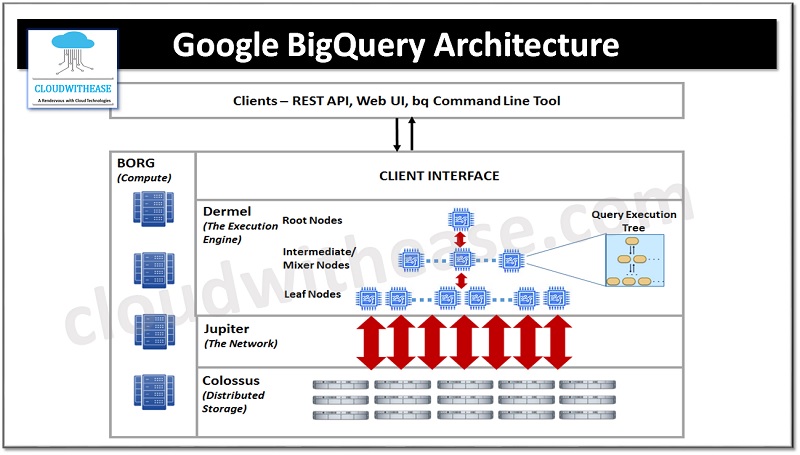
BigQuery was designed for data analysis on billions of rows and can be accessed with a REST API. BigQuery was released in the year 2011 and it has been enhanced over years and new features are added and it was an externalized version of Dremel query service software.
Features of Google BigQuery
- It allows data analytics across several cloud platforms
- Consistent data experience across clouds
- It has built in Machine learning models in BigQuery using SQL queries
- It has in memory analysis capability
- BigQuery Geographic information systems (GIS) provides information about mapping and location
Benefits of BigQuery for Data Warehouse Practitioners
Google BigQuery replaces the traditional data center hardware blues; it acts as a collective store of all analytical data in the organization. It is a data warehouse which organizes data tables into units referred to as ‘data sets’. Datasets are in scope of Google cloud project. When you refer a table from command line in SQL query or using code you can use below construct:
Ct.dataset.table
- The Multiple Scopes – project, dataset and table will help to structure information in a logical manner. Multiple datasets can be used to separate tables having different analytical domains and project level scoping can be used to isolate datasets from one another as per business requirements.
- BigQuery allocates resources to query and storage dynamically based on its usage and requirement. It does not require provisioning of resources in advance. BigQuery allocation of resources is based on usage patterns.
- Storage Resources – allocation and deallocation happens as you consume them such as removing data or dropping tables will deallocate space.
- Query resources are allocated as per query type and its complexity. Each query uses a number of slots, which are computation units which comprise a certain amount of CPU and RAM.
- There is no minimum usage commitment you need to define here. Actual usage devices the allocation of resources and charges. By default, BigQuery customers have 2000 slots for query operations. Fixed number of slots can be reserved for a project.
- It supports multiple data formats such as proprietary format, columnar proprietary format, query access pattern, Google distributed file system and efficient management of storage.
- BigQuery stores data in a proprietary columnar format known as Capacitor. The data is physically stored on Google distributed file system known as Colossus which ensures redundancy using erasure encoding to store redundant chunks of data on several physical disks and data is also replicated to multiple data centres.
- BigQuery queries can be run outside its storage, on data stored in cloud storage, Google drive and Bigtable using federated resources.
- Fully managed and maintainable service. Updates can be achieved without any downtime or performance impact by BigQuery architects. BigQuery doesn’t use indexes so you need not rebuild indexes.
- Provides backup and disaster recovery and users can revert back to previous changes without any need for backup and restoration. It manages backup and disaster recovery at service level and maintains a seven-day history of changes in your tables. BigQuery allows query to point in time snapshot of data using table decorators or SYSTEM_TIME AS OF in FROM clause. When a table is deleted, its history is flushed post seven days.
- Datasets organization can be performed as you can segment datasets into separate projects based on data class or business unit or consolidate into a common project to reduce complexity. The activities can be performed based on role
- Unlike traditional RDBMS systems where you grant permissions to view/modify tables by creation of SQL grant statements and apply them to a given user within the database, BigQuery provides predefined roles to control access to resources. Custom IAM roles can be created with a defined set of permissions and then assign them to users or groups.
- BigQuery puts a limit on maximum rate of incoming requests and enforces quotas on per project basis . it does not support fine grained prioritization of interactive or batch queries.