Table of Contents
Data Analysis can be quite intricate and various attempts have been made to simplify it. There are several analytics tools available, and Amazon Athena, an AWS service provided by the renowned technology enterprise Amazon, is one of them. In this blog, we will understand the working, benefits and limitations of Amazon Athena.
What is Amazon Athena?
Amazon offers a huge selection of services, such as computing, storage, databases, analytics, Internet of Things, security, and more. Data Analytics is also one of these.
Amazon Athena is a tool for interactive data analysis that can process complex queries quickly. It is serverless, so there is no need to create a setup or worry about infrastructure management. Amazon Athena follows ANSI standards, allowing you to query data, including big data, in two easy steps:
- Establishing a direct connection to data sources such as Amazon Simple Storage Service (S3)
- One can access and query data via the Structured Query Language (SQL) by either utilizing the AWS intuitive graphical user interface (GUI) or operating via the command line.
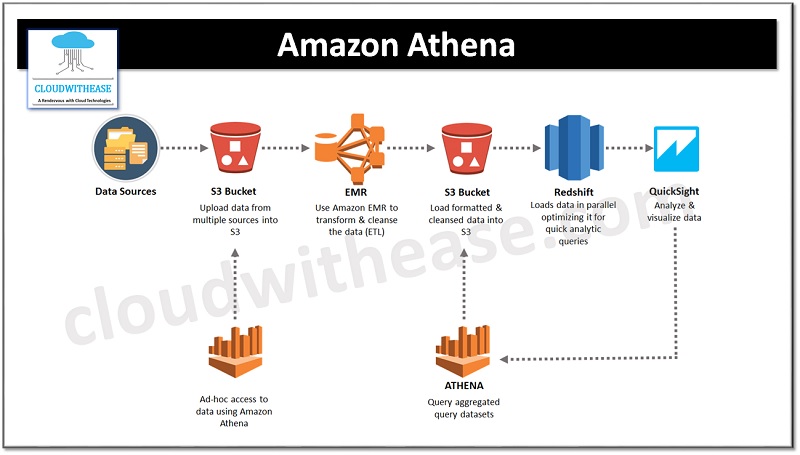
How does Athena work?
AWS data is stored as objects in S3. This data can be in a range of structured or semi-structured formats, for example, plaintext files such as CSV and JSON, application and Amazon Web Services (AWS) service logs, and columnar files like Apache Parquet and Apache ORC.
Once your data is organised, you can construct a table in Athena. This includes a schema (for example, the way the data is ordered) and a location (for example, where the data is kept in S3). However, it doesn’t include any data by itself. Tables are established utilizing the Apache Hive DDL, which is similar to SQL.
In the end, you will create a query in the standard ANSI SQL language and execute it. This query will be divided into several parts and run across hundreds or thousands of cores in the pool of Amazon managed compute. These cores will access the data stored in S3, run the query, and then return the output. Athena uses Presto, an open source distributed SQL engine intended for queries that take up petabytes scale queries.
Benefits of Athena
- Serverless: The user does not need to be concerned about servers, infrastructure, setting up, increasing capacity, or breakdowns since the system is serverless.
- Pay Per Query: Compared to other services like EMR, Athena is more cost-effective since you are only charged for the queries you are running. When no queries are executed, you don’t have to pay anything, leading to a substantial cost reduction.
- Secure: Athena provides total control over the data set through IAM policies and AWS identities. Since the data is in S3 buckets, IAM policies can be used to manage the users’ access.
- Highly Accessible: AWS Athena is open to all, not only to developers and engineers, since it executes inquiries using conventional SQL. The simplicity of the standard SQL queries means that even business analysts and other data experts can utilize them.
- Flexible: The architecture of Amazon Athena is both flexible and accessible, meaning you don’t have to commit to a single vendor, technology, or tool. For instance, you can work with assorted open-source file formats and switch between query engines without having to alter the schema.
- Fast: Athena is a speedy analysis tool that can process intricate queries with great speed. To do this, it splits the query into simpler segments and runs them simultaneously, then combines the results to generate the intended output.
Limitations of AWS Athena
Despite being highly functional and interactive, Athena has some limitations:
- Unpredictable costs: The pay-per-inquiry structure has its pros and cons. If your questions are not well-optimized or if you don’t have a calculated partitioning approach, Athena’s pricing model can become an obstacle.
- Shared Resources: Athena does not allocate dedicated resources for each query; instead, queries are fulfilled by drawing from a shared pool of resources within the same AWS region. Due to this, Athena is not suitable for applications where real-time results are required.
- Unsupported features: Despite being an efficient tool, Athena has some unsupported features e.g. it doesn’t support all DDL statements. It is not possible to insert, update, or delete any data in S3, as it is configured as read-only.
Step-by-Step Guide to use Athena in AWS
1. To begin, create a S3 bucket. Upload a CSV, JSON, or any other type of file that Athena is able to process. (It is advisable to create a separate bucket to learn Athena setup)
2. After you have put the file in S3, you will need to open Athena. For those who have never done it before, the initial step is heading to the settings and defining an output path. This means that any queries you run will have their results stored in the selected S3 bucket.
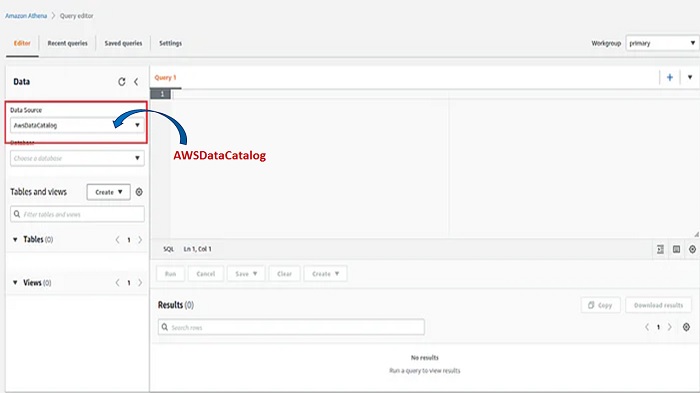
3. In the Editor tab, you will find Data Source and AWS DataCatalog is selected. DataCatalog will analyze the JSON objects inside the S3 bucket of the source data, and ascertain that the JSON file contains the schema. Then it will link up to a pseudo table in Athena in order to query the columns in your JSON file.
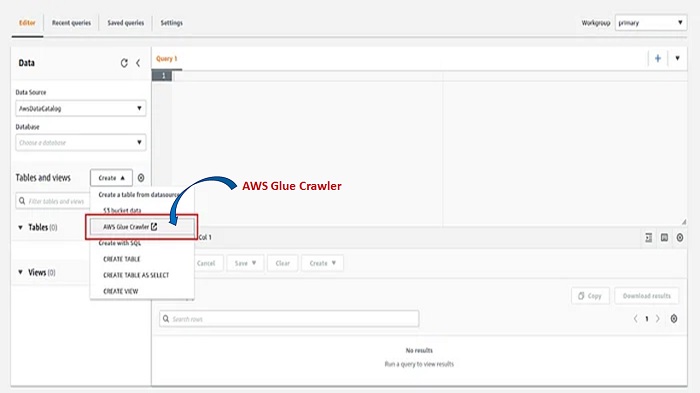
4. After that, click on the option to create and choose AWS Glue Crawler. This will direct you to the AWS Glue page. You can also go with selecting data from an S3 Bucket, but in that case, you will have to state all the details for creating the table yourself, including each column name and other related elements.
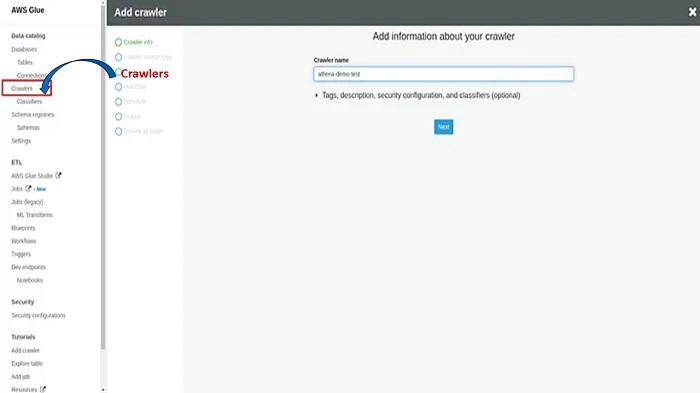
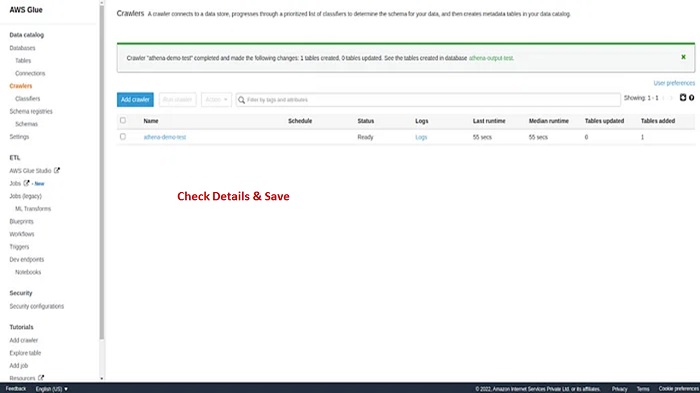
5. Select Crawlers from the left side of the menu.
6. When creating the crawler, ensure that you enter the relevant name and select Data Sources under Crawler Source Type. In the Datastore section, choose S3 and enter the bucket path you created. Attach an IAM role with the required permissions, select Run on-Demand under Schedule, select Default under Database, and click Save. Run the crawler after it is created and you will notice that one table has been added.
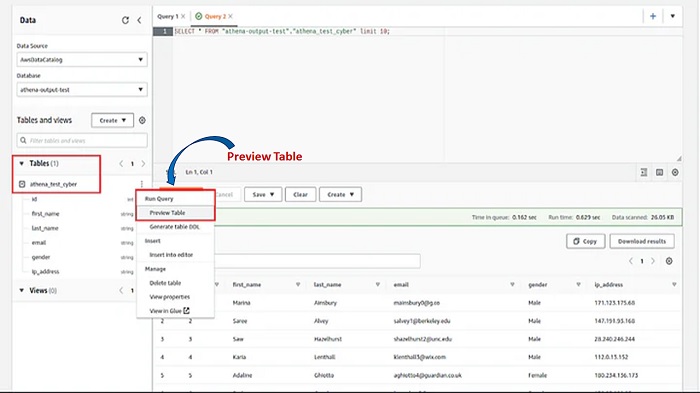
7. Go back to Athena and press the refresh button. You will notice that a new table has been added to the list of tables. Select the table and view the data that is executed from the query.
Final Words
It has been observed that the AWS Athena feature allows users to execute common SQL instructions on data stored in S3. This blog post outlines a number of advantages of utilizing AWS Athena. Is there a pile of data stored in S3 that you need to query? Are you familiar with writing SQL queries? If so, Athena is designed for you.